

数据库性能优化二:数据库表优化
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第二部分
数据库性能优化二:数据库表优化
优化①:设计规范化表,消除数据冗余
数据库范式是确保数据库结构合理,满足各种查询需要、避免数据库操作异常的数据库设计方式。满足范式要求的表,称为规范化表,范式产生于20世纪70年代初,一般表设计满足前三范式就可以,在这里简单介绍一下前三范式
先给大家看一下百度百科给出的定义:
第一范式(1NF)无重复的列
所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
第二范式(2NF)属性
在1NF的基础上,非码属性必须完全依赖于码[在1NF基础上消除非主属性对主码的部分函数依赖]
第三范式(3NF)属性
在1NF基础上,任何非主属性不依赖于其它非主属性[在2NF基础上消除传递依赖]
通俗的给大家解释一下(可能不是最科学、最准确的理解)
第一范式:属性(字段)的原子性约束,要求属性具有原子性,不可再分割;
第二范式:记录的惟一性约束,要求记录有惟一标识,每条记录需要有一个属性来做为实体的唯一标识。
第三范式:属性(字段)冗余性的约束,即任何字段不能由其他字段派生出来,在通俗点就是:主键没有直接关系的数据列必须消除(消除的办法就是再创建一个表来存放他们,当然外键除外)
如果数据库设计达到了完全的标准化,则把所有的表通过关键字连接在一起时,不会出现任何数据的复本(repetition)。标准化的优点是明显的,它避免了数据冗余,自然就节省了空间,也对数据的一致性(consistency)提供了根本的保障,杜绝了数据不一致的现象,同时也提高了效率。
优化②:适当的冗余,增加计算列
数据库设计的实用原则是:在数据冗余和处理速度之间找到合适的平衡点
满足范式的表一定是规范化的表,但不一定是最佳的设计。很多情况下会为了提高数据库的运行效率,常常需要降低范式标准:适当增加冗余,达到以空间换时间的目的。比如我们有一个表,产品名称,单价,库存量,总价值。这个表是不满足第三范式的,因为“总价值”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“总价值”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。合理的冗余可以分散数据量大的表的并发压力,也可以加快特殊查询的速度,冗余字段可以有效减少数据库表的连接,提高效率。
其中"总价值"就是一个计算列,在数据库中有两种类型:数据列和计算列,数据列就是需要我们手动或者程序给予赋值的列,计算列是源于表中其他的数据计算得来,比如这里的"总价值"
在SQL中创建计算列:
create table table1
(
number decimal(18,4),
price money,
Amount as number*price --这里就是计算列
)
也可以再表设计中,直接手动添加或修改列属性即可:如下图
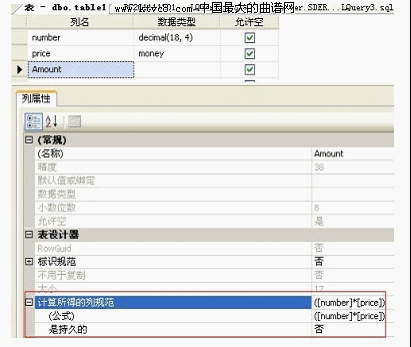
是否持久性,我们也需要注意:
如果是'否',说明这列是虚拟列,每次查询的时候计算一次,而且那么它是不可以用来做check,foreign key或not null约束。
如果是'是',就是真实的列,不需要每次都计算,可以再此列上创建索引等等。
优化③:索引
索引是一个表优化的重要指标,在表优化中占有极其重要的成分,所以将单独写一章”SQL索引一步到位“去告诉大家如何建立和优化索引
优化④:主键和外键的必要性
主键与外键的设计,在全局数据库的设计中,占有重要地位。 因为:主键是实体的抽象,主键与外键的配对,表示实体之间的连接。
主键:根据第二范式,需要有一个字段去标识这条记录,主键无疑是最好的标识,但是很多表也不一定需要主键,但是对于数据量大,查询频繁的数据库表,一定要有主键,主键可以增加效率、防止重复等优点。
主键的选择也比较重要,一般选择总的长度小的键,小的键的比较速度快,同时小的键可以使主键的B树结构的层次更少。
主键的选择还要注意组合主键的字段次序,对于组合主键来说,不同的字段次序的主键的性能差别可能会很大,一般应该选择重复率低、单独或者组合查询可能性大的字段放在前面。
外键:外键作为数据库对象,很多人认为麻烦而不用,实际上,外键在大部分情况下是很有用的,理由是:外键是最高效的一致性维护方法
数据库的一致性要求,依次可以用外键、CHECK约束、规则约束、触发器、客户端程序,一般认为,离数据越近的方法效率越高。<
《数据库性能优化二:数据库表优化》有关声明
| 评论人 | 评论内容摘要(共 0 条,查看完整内容) 得分 0 分 | 发表时间 | |